
The ability for organizations to data mine and address a wide range of business problems
across many industries is a huge asset in terms of ROI.
What about big data and analytics helping not only the bottom line but also the general public?
What about all the data that envelops a single patient and his/her likeliness to do a set of ordinal outcomes?
Let’s consider patients with type one diabetes. Constantly these patients are asked to regurgitate a string of numbers that make up their medical history and how their blood glucose levels have been performing. Luckily, due to drastic improvements in technology, a diabetic’s meter can hold up to three months of glucose readings, insulin, and carbohydrate intake. But what is actually becoming of this data? Most doctors focus heavily on line-by-line reports, circling where they see hyper or hypo-glycemia, but there are many more interactions that play into the patients’ blood glucose levels in the next month.
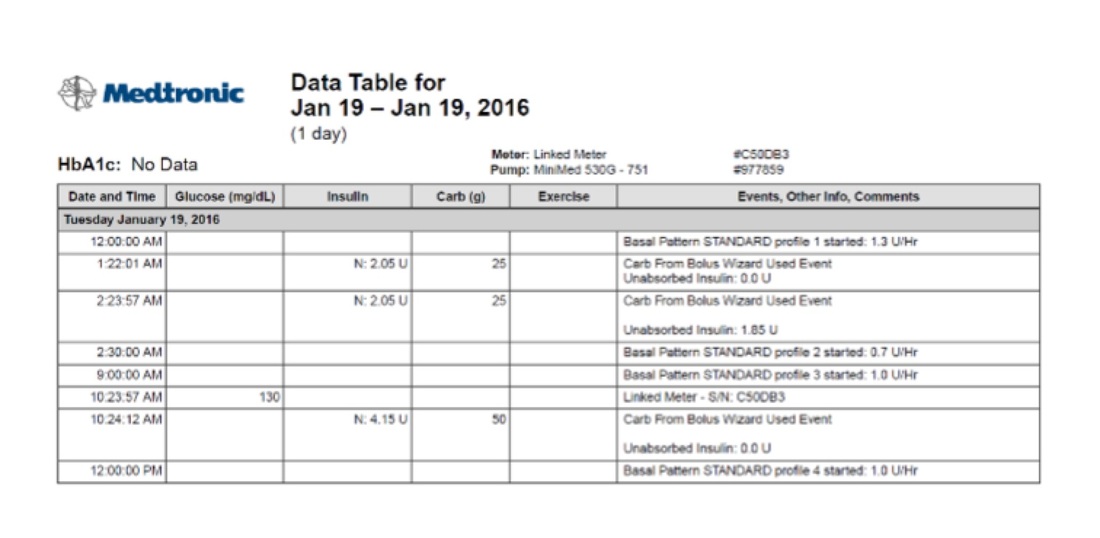
Combining my interest in analytics and my enthusiasm for volunteering with JRDF (Juvenile Diabetes Research Foundation), I was able to randomly generate information that mimicked what diabetics can download off of their devices in the form of a CSV file. Not only were their blood sugar readings in there, but there was insulin intake, carb intake, types of insulin delivered, whether it was before a meal or after a meal, and when they exercised, all in perfect comma-separated columns with consistent time stamps. With little to no experience in R but an intense passion for data analysis, I taught myself how to script inside the R console.
I developed a script that pulls in a patient’s CSV automatically from their device, cleans the data as needed, and appends the incoming results to a master file, which generates reports including insightful visualizations for quick interpretations. The most appealing part of the process is the creation of time series projections for blood glucose readings that account for interactions from carbohydrate intake even when doctors make a change to their patients’ insulin regimen. But it wasn’t enough. After watching tutorials in Shiny, bothering Dr. LaBarr, and talking with my classmates, I developed a web application that a patient can now send to their doctor and view updates.
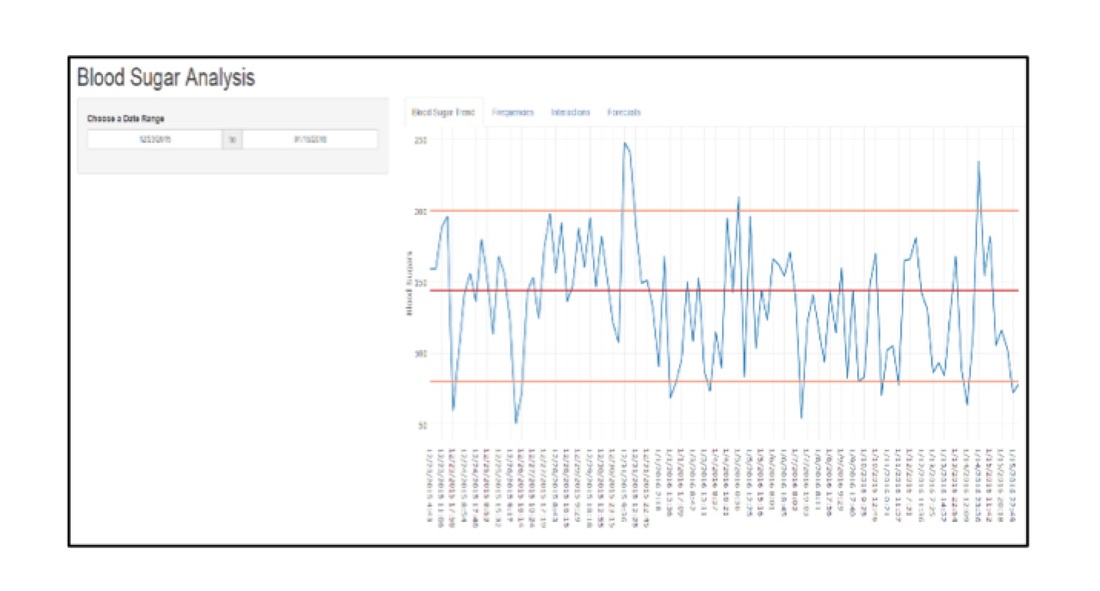
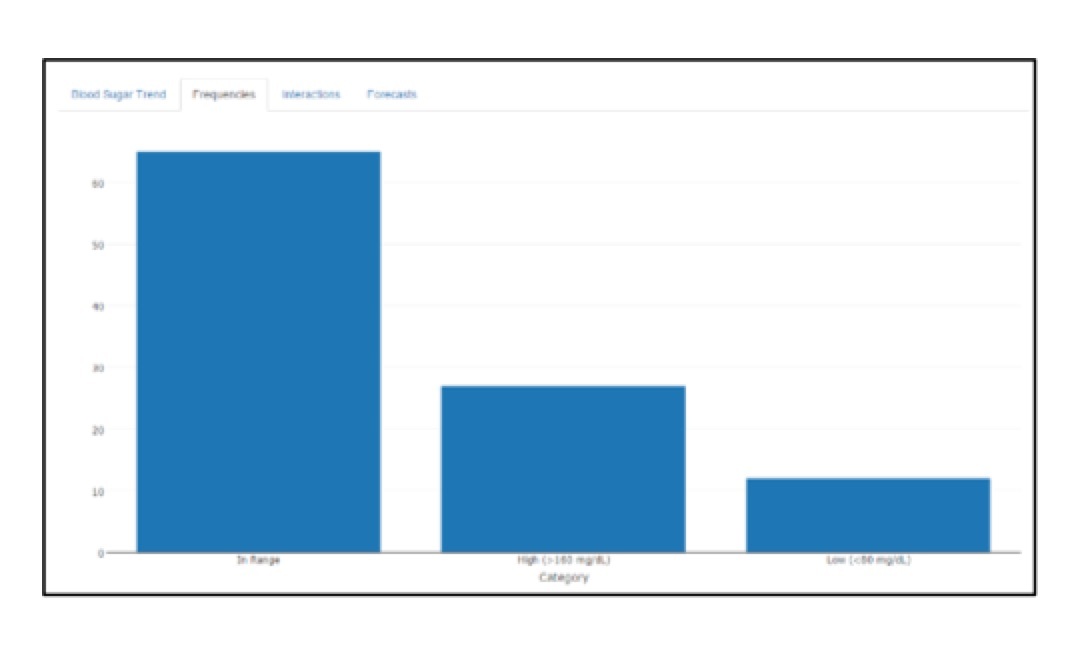
I know this is still not enough; a diabetic is producing data even as I am writing this column, and I am excited about implementing new techniques I am learning at the Institute. What about automating it? What if I can develop something that does this automatically every two weeks without running a program? What if insulin pumps can see these results and adjust insulin levels automatically? Can this eventually be done? I guess it depends. One thing I know for sure is that enthusiasm for big data can impact businesses and the world.
Columnist: Matthew Russell
