
“Just as electricity transformed almost everything 100 years ago, today I actually have a hard time thinking of an industry that I don’t think AI will transform in the next several years,” – Andrew Ng, Former Baidu Chief Scientist, Coursera Co-Founder and Stanford Professor
Artificial intelligence, long a mainstay of speculative fiction and popular imagination, has advanced at breakneck speed in the past few decades to become one of the fastest-growing fields in technology. Much of this success can be credited to improvements in machine learning algorithms: the methodologies that allow computers to automate statistical models and make predictions about the world around them. Certain machine learning algorithms have improved to the point where even the most complex information systems seem within AI’s reach.
One such system is human language, or “natural language,” as it is often called in artificial intelligence and computer science. Natural Language Understanding (NLU) is considered to be an “AI-complete” problem, or a problem that is so complex that solving it would theoretically be to solve the central problem of artificial intelligence — to make a computer as intelligent as a human being. This idea has persisted for over half a century and is summed up neatly by the famous Turing Test developed by Alan Turing in 1950. A computer passes the Turing Test if a human evaluator is unable to distinguish the computer from a human control in a blind test. In 2014, a computer named Eugene Goostman is said to have passed the Turing Test — though there is some skepticism about that claim due to the fact that researchers chose to present Eugene as a 13-year-old, non-native speaker with imperfect English conversational skills. In addition, the test itself has been criticized by many artificial intelligence researchers. However, it holds a fascination for scientists and laypeople alike, and Natural Language Processing (NLP) and NLU remain central issues in the field of artificial intelligence.
Neural networks have emerged in the past five to ten years as an extremely effective tool for solving NLP problems. Neural networks are a branch of machine learning in which inputs are passed through one or more “hidden layers” of mathematically-weighted parameters before eventually producing probabilities for a given outcome. This computational configuration allows the algorithm to determine complex relationships that are hidden from the human eye or patterns that are difficult to perceive. In some ways, the results in the early layers are comparable to introducing polynomial inputs into your data (think of the U-shaped quadratic form or the S-shaped cubic): they make it easier to introduce complexity into your model. In the case of NLP, these inputs are normally long lists of words or even letters. For example: is this set of words in this order more likely to be part of a spam email or a non-spam email?
Image recognition (another AI-complete problem, and another field in which neural networks are used often) provides a helpful visual for how complexity increases with each hidden layer. Below, the output of the algorithm (where the input is a long list of pixels) is shown first, followed by the images it can classify. The first layer of the algorithm can recognize a variety of straight lines. The second layer introduces simple curves. By layer 4, you can clearly see dog’s faces in the output of the algorithm, which can be overlaid onto the photos of dogs for the purpose of image recognition.



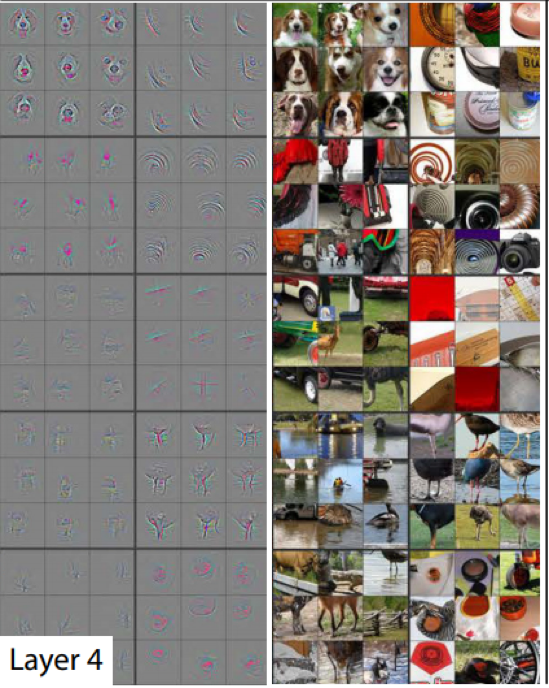
Images from Visualizing and Understanding Convolutional Networks by Matthew D. Zeiler and Rob Fergus
Traditional neural networks assume that input variables are independent from each other. In the image recognition example, for instance, the assumption is that the color of one pixel doesn’t necessarily affect the color of the pixel next to it, and so on. In language, however, order matters tremendously, both at the level of the word and at the level of the character. Think of a word like “set,” which has the largest number of dictionary definitions of any word in the English language. In the phrases, “he sets” and “the sets,” the word means something very different. “Sets” is far from the only example of words in the English language with context-dependent meaning, and these differences in meaning can greatly affect tasks in both NLU (e.g., information extraction, sentiment analysis) and NLP (e.g., text generation).
The solution is a special type of neural network known as “recurrent neural networks” (or RNNs). These networks take order into account, and therefore output depends on previous calculations, creating something of a “short-term memory” in the algorithm itself. Character-level RNN models generate text one letter at a time using this memory of previous characters. To get more details about how this model works, check out Andrej Karpathy’s blog post, The Unreasonable Effectiveness of Recurrent Neural Networks.
With large enough training sets, RNNs can create original language of their own, with varying degrees of success. Janelle Shane, creator of the blog Lewis and Quark, trains this technology to generate everything from hamster names to recipe titles to metal band names. Shane’s creations aren’t likely to pass a Turing Test anytime soon, but they are often very funny. Take for instance this list of paint names, generated by RNN:

While the output is silly and amusing to human readers, there are several aspects of the generated words that are quite impressive given that it built each name character-by-character. The first is that none of the combinations of letters in the words violate what linguists call “phonology” – that is, the sound patterns of English. One can easily imagine a randomly generated sequence of letters that does not follow the rules of English, for instance a word like “tbar” would be unacceptable in English because we do not allow the sounds “t” and “b” to be next to one another in a word. This is true even of the made-up words, like “Turdly” and “Stummy.”
Another impressive attribute is the fact that some of the colors are actually correctly recognized by the algorithm — it correctly identifies blue twice, for instance, and beige. This indicates a level of semantic understanding by the algorithm, for it to match word to meaning in any of the cases.
Although no one could indisputably claim that NLP has been solved in its entirety, RNNs are changing the field of NLP in a way that few would have predicted even recently. Previous generations of AI researchers and computational linguists have plugged away at long, complicated hard-coded algorithms intended to do something as simple as extract a person’s name from a document or classify a phrase as a place name. I know this because I was one of those computational linguists, using my knowledge of linguistics and creating hundreds of lines of code to allow the computer determine whether “John Smith” was a judge or an attorney. Computational linguists and other natural language processing experts can now use RNN and other machine learning methods to automate even the minutiae of the process, allowing computers to find the complex patterns of human language for them – in just a few lines of code. As a student at the IAA, I will be able to master these more sophisticated techniques and come closer to my goal of being on the cutting edge of the field of natural language processing.
Columnist: Amy Hemmeter